I bought a hifiberry amp (a 2x25W class D amplifier with a fully digital path from the raspberry) and a PiTFT 2.8″ touchscreen. I’m planning to integrate them with my raspberry pi model B inside in a set of Mission 731i speakers. That will give me a set of powered speakers that can stream music over a wifi network, with a touchscreen interface.
First thing to do was to connect both the hifiberry amp and and pitft to the same raspberry. They are designed to run exclusively on top of a raspberry, but they use different pins, except for the 5V power pin. So after wiring them carefully with jumper cables I managed to run them simultaneously.

The raspberry will run squeezelite, so it will act as a squeezebox player. Squeezelite is a headless application, so it does not provide any interface that can be controlled from the touchscreen. The sqeezelite player is controlled by a squeezebox server (also called logitech media server).
I decided to build a GTK app with glade and python to run on the touchscreen (and obviously I’ll use Bluefish to do the python coding). I previously used pygtk or gtk with C, so first I had to learn the new way to use gtk3 in python, but that turned out to be fairly simple. I start the app in .xinitrc without any window manager or decorations, so it runs fullscreen without any possibility to switch to another application. Startx is called from .profile if the tty is tty1, and tty1 is set for auto-logon – so power on means boot, X and then the app.
The app also has to control the squeezelite process. I created an gtk timer callback check_processes() that is called every second and checks if the squeezelite process is still running:
def start_procsqueezelite(self):
try:
self.procsqueezelite = subprocess.Popen([config['squeezelite'], '-n', 'SqueezeSpeaker'])
except OSError as err:
print 'error starting',config['squeezelite'],err
def check_processes(self):
if (self.procsqueezelite):
ret = self.procsqueezelite.poll()
else:
ret = 255
if (ret != None):
self.start_procsqueezelite()
return 1
Second challenge was to control the squeezebox server from the app. Luckily the squeezebox server uses a very simple protocol, a tcp connection to port 9090 with ascii line based commands and urlencoded results. The next button can simply send the command “aa:bb:cc:dd:ee:ff playlist index +1”, pause sends “aa:bb:cc:dd:ee:ff playlist mode pause”, etc. Basic functionality was working quickly.
However, any squeezebox player can be controlled from any device (smartphone, tablet, etc.), so another device might be changing the volume, pressing pause, etc. and my app should display the new corresponding status. The squeezebox server has a “listen” command for that, this will send any event over the tcp connection, again line based and urlencoded. I chose to open a second tcp connection. To make the application respond quickly, both when doing socket I/O and responding to GUI events, I run the connections in separate threads. The commands are put into a python Queue, and the threads send their results to the mainloop using an idle callback. In the idle callback I use regex matching to find the interesting events and update the GUI accordingly.
Something that took me some time (and then turned out to be very simple) was how to load the album covers in the GTK GUI. The Squeezeserver has them available over http. The dirty approach was to download them, and then load them from file. The nice way is to download them to memory and load them into the widget. The http loading has again a separate thread, which again sends the loaded data with an idle callback to the mainloop. This is the idle callback:
def artwork_handler(self,imgdata):
image = self.builder.get_object('coverimage')
pbl = GdkPixbuf.PixbufLoader()
pbl.set_size(80,80)
try:
pbl.write(imgdata)
image.set_from_pixbuf(pbl.get_pixbuf())
except:
print 'artwork_handler, failed to parse image data'
pbl.close()
return 0
The resulting app looks like this when running on my desktop:
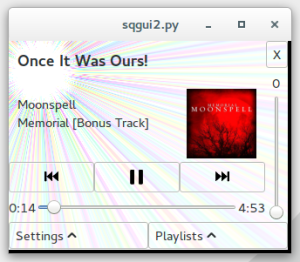
I’ll probably use a dark theme when running on the PiTFT. More on this project later, and I’ll publish the full code soon.